mysql中ON DUPLICATE KEY UPDATE语法分析
[ON DUPLICATE KEY UPDATE用武之地]
如果表里没有则insert,若有了则update就需要用到mysql ON DUPLICATE KEY UPDATE语法;就样就可以在代码里少写if语句来判断了
[实例讲解]
表结构
CREATE TABLE `spk_goods` (
`gid` int(11) NOT NULL auto_increment COMMENT '货物id',
`cid` int(11) NOT NULL COMMENT '所属分类id',
`name` char(30) NOT NULL COMMENT '货物名称',
PRIMARY KEY (`gid`),
UNIQUE KEY `NewIndex1` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8
现有的表记录
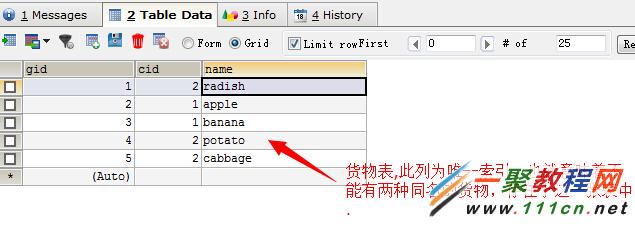
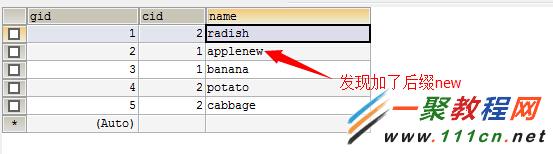
那么问题来了,现有一个需求。要求插入一个新的货物。若此货物在表中已经存在,则在货物名称在以前的基础上加一个后缀new;若以不存在此货物,则插入到数据库,用一条sql完成
测试一:插入表中已有的记录
sql如下:
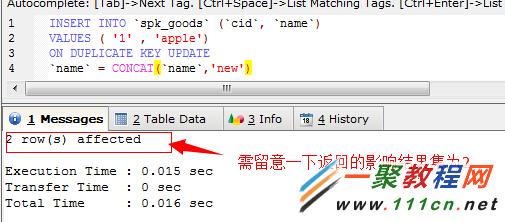
INSERT INTO `spk_goods` (`cid`, `name`)
VALUES ( '1' , 'apple')
ON DUPLICATE KEY UPDATE
`name` = CONCAT(`name`,'new')
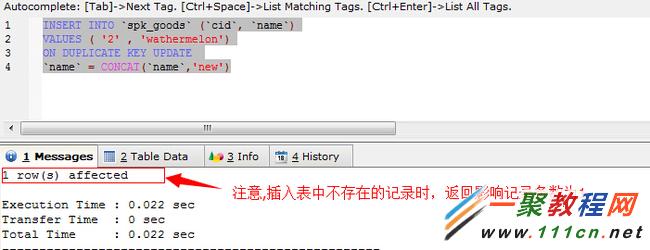
INSERT INTO `spk_goods` (`cid`, `name`)
VALUES ( '2' , 'wathermelon')
ON DUPLICATE KEY UPDATE
`name` = CONCAT(`name`,'new')
执行sql查看记录变化
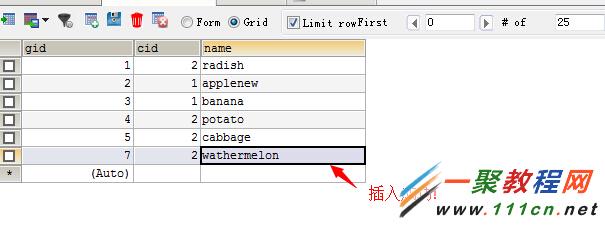
举个例子,字段a被定义为UNIQUE,并且原数据库表table中已存在记录(2,2,9)和(3,2,1),如果插入记录的a值与原有记录重复,则更新原有记录,否则插入新行:
代码如下:
INSERT INTO TABLE (a,b,c) VALUES
(1,2,3),
(2,5,7),
(3,3,6),
(4,8,2)
ON DUPLICATE KEY UPDATE b=VALUES(b);
以上SQL语句的执行,发现(2,5,7)中的a与原有记录(2,2,9)发生唯一值冲突,则执行ON DUPLICATE KEY UPDATE,将原有记录(2,2,9)更新成(2,5,9),将(3,2,1)更新成(3,3,1),插入新记录(1,2,3)和(4,8,2)




